overleaf template galleryLaTeX templates and examples — Recent
Discover LaTeX templates and examples to help with everything from writing a journal article to using a specific LaTeX package.

This example demonstrates how to produce diagonal lines in table cells using the slashbox and diagbox packages. The diagonal line produced by the slashbox package is rather jagged and unwieldy. The diagbox package does a better job in general. Try loading only one of these packages to see the difference — if diagbox is loaded at all, it overrides slashbox's behavior./p>

A performance time evaluation between a C lexer and a Lex generated lexer.
Série de Estudos Bíblicos sobre as Parábolas proferidas por Jesus Cristo

A business plan

Custom presentation template with biblatex
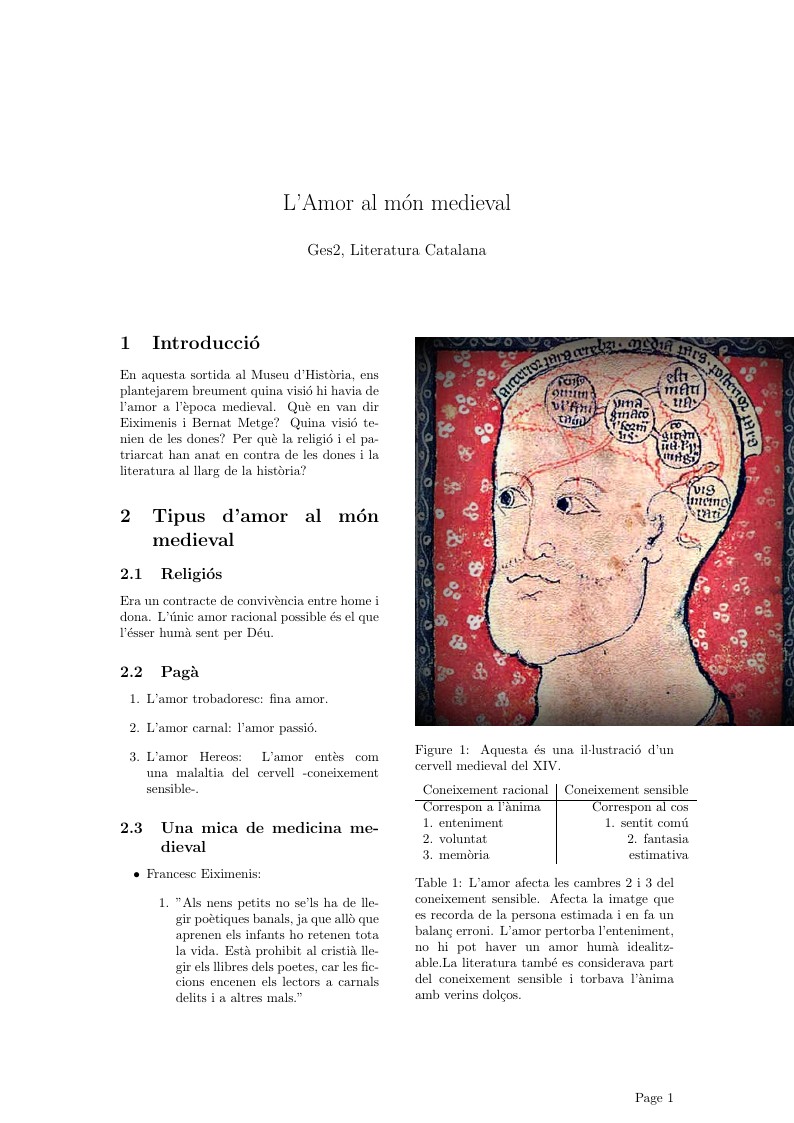
Breu resum sobre l'amor al món medieval. Basat en apunts de l'assignatura de la UB.

This is a sample lab report format for PHYS 349 at the University of Redlands.

This form shows how to use LaTeX to simulate a word form. All elements in the form could be rendered by LaTeX. Office forms could also be written with LaTeX.

Template utilizado para os relatórios dos laboratórios de OAC. Pode ser que seja utilizado em outras disciplinas lecionada pelo professor
\begin
Discover why over 25 million people worldwide trust Overleaf with their work.